| images | ||
| Modelfiles | ||
| README.md | ||
Install Ollama
curl -fsSL https://ollama.com/install.sh | sh
I prefer to make the model files available for all computers in our working group. Thus I put them on a NAS under /data_1/deepseek.
In that case you want to change /etc/systemd/system/ollama.service and add your directory to it:
Environment= [PATH BLA BLA] "OLLAMA_MODELS=/data_1/deepseek/models" "HOME=/data_1/deepseek"
After that restart systemd with:
systemctl restart ollama.service
Check the status of the service:
systemctl status ollama.service
Getting the models
Now we can get the models:
ollama pull deepseek-r1:1.5b
ollama pull deepseek-r1:7b
ollama pull deepseek-r1:8b
ollama pull deepseek-r1:32b
ollama pull deepseek-r1:14b
ollama pull deepseek-r1:70b
However, you want to check first which model you want based on the CPU RAM or the GPU VRAM you have:
ollama list | grep deepseek
deepseek-r1:1.5b a42b25d8c10a 1.1 GB
deepseek-r1:671b 739e1b229ad7 404 GB
deepseek-r1:32b 38056bbcbb2d 19 GB
deepseek-r1:14b ea35dfe18182 9.0 GB
deepseek-r1:7b 0a8c26691023 4.7 GB
deepseek-r1:70b 0c1615a8ca32 42 GB
deepseek-r1:8b 28f8fd6cdc67 4.9 GB
Test
ollama run deepseek-r1:1.5b
>>> Hello
<think>
</think>
Hello! How can I assist you today? 😊
>>> /bye
Using it with VS Code
For using Ollama we need a special setting for VS Code. Thus we need to produce instances with different model parameter (or in other words: got to the Modelfile subfolder and check the information their)
code_ds32b:latest 995e2d04e071 19 GB
code_ds70b:latest 4930f987452d 42 GB
code_ds7b:latest 0438bd669fa8 4.7 GB
code_ds8b:latest 643346a4074c 4.9 GB
code_ds1.5b:latest 2d66604e7b60 1.1 GB
code_ds14b:latest 76c930e3d70a 9.0 GB
Do not you larger models on your CPU or you will die of old age!
Install roo code
Please make sure that your shell doesn't use something like Starship or the posh packages! Otherwise VS Code can not run terminal command!
Setting of roo code
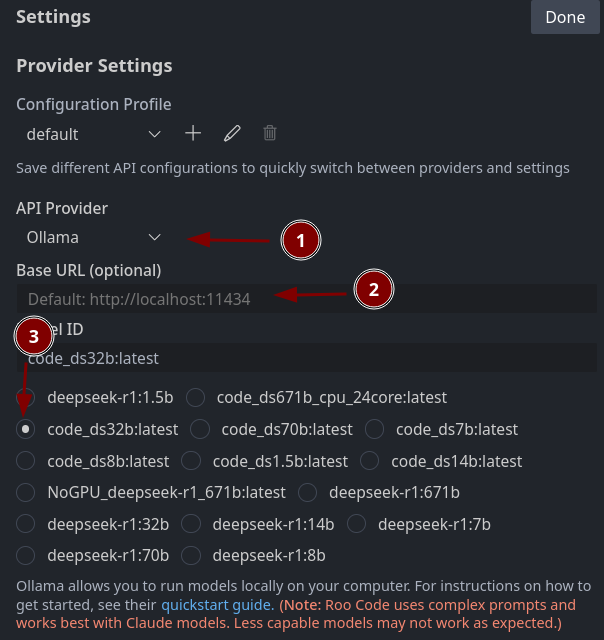
You need to select Ollama. Then you need to connect to Ollama. If Ollama is local on your machine, you don't so anything here. For home office I use
ssh -p [PORT OLLAMA SERVER] -L 11434:127.0.0.1:11434 [USERNAME]@[IP OLLAMA SERVER]
to connect directly to the computer with Ollama and tunnel the 11434 to my local machine. (Or in other words: I make the external Ollama available as local service on port 11434).
Select a code model, which you created by using the modelfiles.
Trust issues
Now you need to decide how much trust you have and allow Roo Code to do stuff without asking you all the time.
And don't ask me what MCPs servers are. I don't know... yet.
